





莊司 慶行

研究概要
莊司研究室では、みんなが本当に必要な情報を必要な時に使えるようにするための、ウェブ情報アクセス技術の研究をしています。
そのために、情報検索システムや知識抽出アルゴリズムの研究、ウェブデータからの人間と社会の分析などの研究を、幅広く行っています。
現代のウェブは、もはや単なる文書の集合ではありません。コミュニケーションの場であったり、ビジネスの場であったり、人間的・社会的側面を含むメディアになりつつあります。このような「ソーシャルウェブ」においてコンテンツを検索し、有用な知識を発見するためには、コンピュータが人間の性質や社会の仕組みを理解している必要があります。
私の研究では、主に2つのアプローチでソーシャルメディア化するウェブに立ち向かっています。1つめは、SNSなどのユーザ発信型メディアにおける、ユーザのリアクションや投稿者のプロファイルといった人間的な情報をウェブ検索や知識抽出に用いるアプローチです。2つめは、集団の多様性や個人の信頼性などの社会科学や認知科学の知見を情報学分野に持ち込んで、リンク解析などのアルゴリズムにその要素を組み込むアプローチです。データベース技術を基盤に、大規模なウェブデータをハンドリングして分析したり、実際にウェブシステムを作成して被験者実験を行ったりしながら研究を進めています。
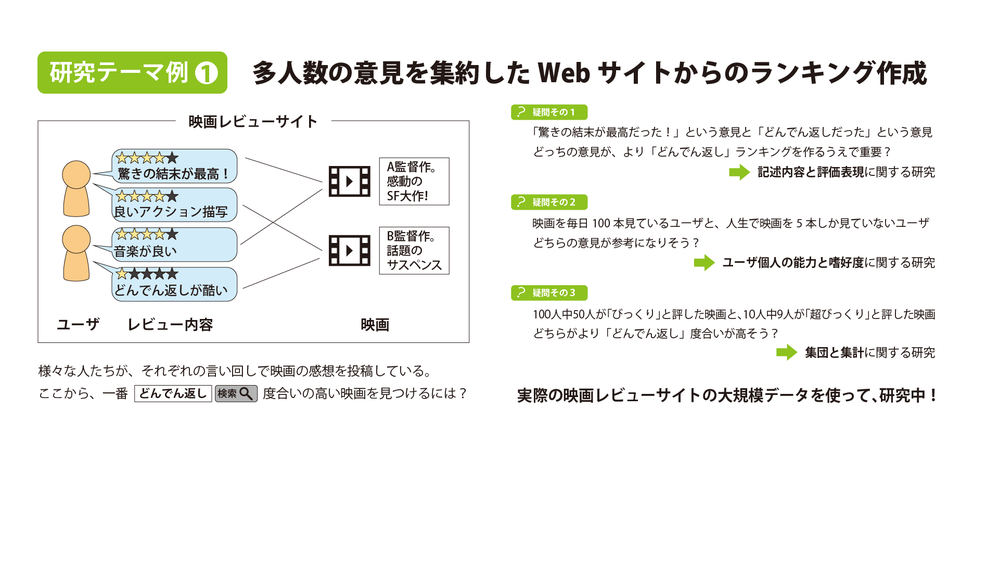
多人数の意見を集約する情報検索技術
現代のウェブは、多人数のコミュニケーションの副産物の集合体になりつつあります。例えば、見たい映画を探す場合にも、「公式サイトであらすじや商品情報から探す」という探し方よりも、むしろ「レビューサイトで評判の良い映画を見る」や、「SNSで映画に詳しい人が勧めている映画を見る」ということが増えてきています。一方で、こうした調べかたは、レビューを1件ずつ読まないといけないので時間がかかり、なおかつネタバレを踏む可能性も高くなります。
そこで、私たちは、こうした環境下でアイテムを発見可能にするために、「多人数の意見をまとめて、人間が意見を直接読まなくてもアイテムを検索可能にする」という研究を進めています。具体的には、「泣ける映画が見たい」と思った際に、検索システムが勝手にレビューを読み進めて、「この映画は、10人の人が『ハンカチがぐしょぐしょになった』と言っているから、泣ける度は0.8ポイントくらいだ」などと映画を判定し、ランキングを作ってくれるようにしています。
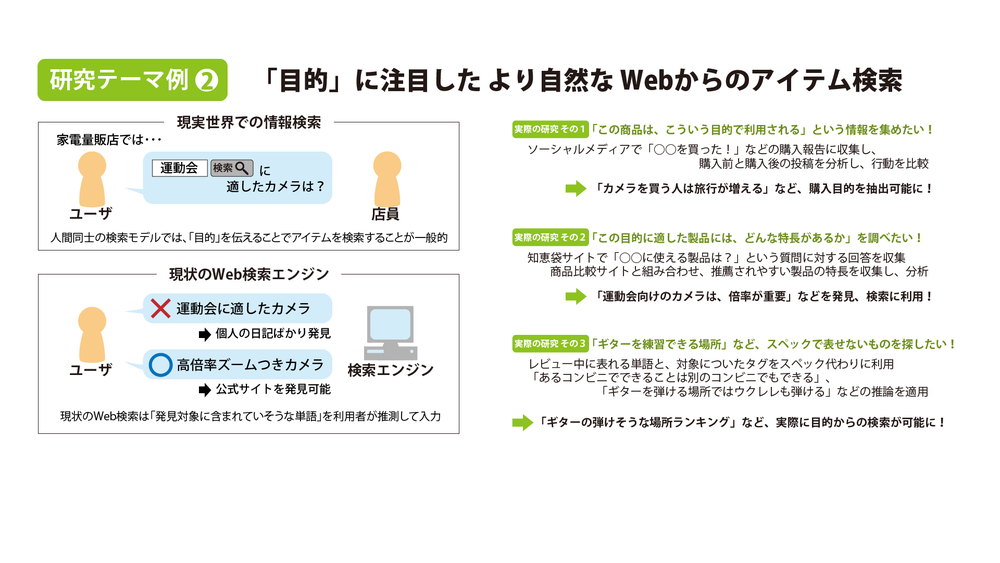
「目的」を直接入力可能な情報検索技術
「検索」という行為は、本来、知らないことを調べるための行為です。ところが、現代のウェブ検索エンジンは、検索キーワードを入力すると、「その単語を含んでいる文書」を発見してきます。そのため、利用者は、自分が知識のない分野でも、常に「正解となる文書に含まれていそうな単語」を推測して入力しています。
そこで、私たちは、知らない分野でも必要な情報を探せるように、人間同士のコミュニケーションに近い検索を可能にするアルゴリズムについて研究しています。普段、私たちがお店で商品を探す際には、「F値の最も高いカメラが欲しい」というような探し方はせずに、「夜でもくっきり人の顔を写せるカメラが欲しい」というように、利用目的を店員さんに伝えています。このような検索を可能にするために、レビュー情報やソーシャルメディア投稿を分析し、機械学習やAI技術で実際に商品や場所を検索可能にしています。
記憶に残る / 記憶に残らないでもよくする情報アクセス技術
現代人は、1日に3時間程度を、インターネットの閲覧に使っているといわれています。一方で、インターネットで見た内容は、実はほとんど記憶に残っておらず、「Web検索の4割は、前に調べたことを調べなおしているだけ」という研究結果も報告されています。
そこで、私たちは、「インターネットで見た情報を覚えやすくすることで、後から再びアクセスする必要をなくす」という解決策と、「インターネットをいちいち見かえさなくても、状況に合わせて必要な情報が降ってくる」という、2つのアプローチで研究を進めています。
インターネットで見た情報を覚えやすくするアプローチとして、毎日寝る前にその日のインターネット閲覧内容をミニテストにして答えたり、カードにまとめたりするといった方法や、見た商品情報を印象深いキャッチコピーにするなどの研究をしています。
インターネットで見た情報を覚えなくてよくするアプローチとして、インターネットアクセス履歴を分析して、スマホの位置情報に合わせて「昨日調べてたアレ、この近くで売ってるよ!」と通知を出すシステムなどについて研究を進めています。
